The heat arrived once again and I was feeling that my Raspberry Pi was too warm considering that it has the official built-in fan, with temperatures easily rising above 60ºC.
Since I installed Ubuntu on it, the fan didn’t seem to work right, but that’s something that has been solved in the recent versions of the kernel.
So here’s how you can set it up in Ubuntu and display it’s status.
Content
Fan check
First of all let's check that our fan is working correctly by managing it manually.
Update your system so you can get the latest fixes that affect the fan. My latest version is Ubuntu Linux 24.04.2.
Now you should be able to turn on the fan manually by typing the following command in the terminal:
echo 4 | sudo tee /sys/class/thermal/cooling_device0/cur_state
A value of 4 will turn on the fan in it's maximum revolutions. You can change this value from 0 to 4.
If the above worked correctly you will hear significant noise from your fan. Now you can turn it off again by echoing a value of 0:
echo 0 | sudo tee /sys/class/thermal/cooling_device0/cur_state
So you see that altering the value in the cur_sate file manually changes the fan speed. That's exactly what the fan daemon does once it's configured, so we will monitor this value later to find out if our fan is working (returned value != 0):
cat /sys/class/thermal/cooling_device0/cur_state
Fan setup
The fan wasn't preconfigured in the earlier versions of the Ubuntu kernel for the Raspberry Pi. I'm not sure if it is now by default, but just check it by editing the config.txt file located in /boot/firmware and find out some lines similar to the following:
Today I’m sharing a very simple yet effective and elegant PS5 controller hanger.
Some concept/design images:
It just stands on its own without any screwing or glueing. It hangs from the PS5 itself and it’s expandable by design (probably you can fit up to 4 controllers just on one side).
If you find issues with your python version not finding a compatible circuit python version, include --break-system-packages at the end. (It wont break anything today, but don't get used to it...)
Use a site like pinout.xyz to find a suitable wiring configuration.
You're ready to do some tests before making your final move to the PCB.
Script config
You can try Adafruit's demo script. Just make sure that you choose the right display and update any changes to the ping assignment (use IO numbers/names rather than physical pin numbers):
# Configuration for CS and DC pins (adjust to your wiring):
cs_pin = digitalio.DigitalInOut(board.CE0)
dc_pin = digitalio.DigitalInOut(board.D24)
reset_pin = digitalio.DigitalInOut(board.D25)
# Setup SPI bus using hardware SPI:
spi = board.SPI()
disp = ssd1351.SSD1351(spi, rotation=270, # 1.5" SSD1351
cs=cs_pin,
dc=dc_pin,
rst=reset_pin,
baudrate=BAUDRATE
)
The truth is that resin printing is next level. Despite the complications of cleaning, the result is really incredible, and today I’m showing you my first print in the Anycubic Photon Mono X2: a Batman you can hang in your living-room with his grappling gun.
Content
Models
The print that you see is made of two free models. That's why here's a huge thank to the authors and my reference to their work:
All I've done is to add an armature to the model giving it the desired pose, and then sticking the gun to its hand. So here is my model so you can print it just as shown.
To finish the figure, you can create a cape and a hook so it can be hanged.
Cape
For the cape I've cut out a piece of fabric from an old sportswear. This is common clothing that's usually black and with an adequate brightness and texture.
Start cutting a square piece and then give it some shape.
In the top part, wrap a wire that will let you adjust the cape around the figure's neck.
Hook
Just find some kind of hook or clamp that lets you tie a thin thread around it. I've used this small paper clamp that I can hook in the books of my shelf.
And that's how you get your awesome Batman hanging in your living-room. Hope you liked it, and any ideas or comments, drop them on Twitter!
PAL is a simplified version of my python home assistant that I’m running in the DFRobot UNIHIKER which I’m releasing as free open-source.
This is just a demonstration for voice-recognition command-triggering simplicity using python and hopefully will serve as a guide for your own assistant.
Current version: v0.2.0(updated september 2024)
Content
Features
Current version includes the following:
Voice recognition: using open-source SpeechRecognition python library, returns an array of all the recognised audio strings.
Weather forecast: using World Meteorological Organization API data, provides today's weather and the forecast for the 3 coming days. Includes WMO weather icons.
Local temperature: reads local BMP-280 temperature sensor to provide a room temperature indicator.
IoT HTTP commands: basic workflow to control IoT smart home devices using HTTP commands. Currently turns ON and OFF a Shelly2.5 smart switch.
Power-save mode: controls brightness to lower power consumption.
Connection manager: regularly checks wifi and pings to the internet to restore connection when it's lost.
PAL voice samples: cloned voice of PAL from "The Mitchells vs. The Machines" using the AI voice model CoquiAI-TTS v2.
UNIHIKER buttons: button A enables a simple menu (this is thought to enable a more complex menu in the future).
Touchscreen controls: restore brightness (center), switch program (left) and close program (right), when touching different areas of the screen.
At the moment, PAL v0.2.0 only includes functionality for Shelly2.5 for demonstration purposes.
Use variables lampBrand, lampChannel and lampIP to suit your Shelly2.5 configuration.
This is just as an example to show how different devices could be configured. These variables should be used to change the particularities of the HTTP command that is sent to different IoT devices.
More devices will be added in future releases, like Shelly1, ShellyDimmer, Sonoff D1, etc.
Power save mode
Power saving reduces the brightness of the device in order to reduce the power consumption of the UNIHIKER. This is done using the system command "brightness".
Change "ps_mode" variable to enable ("1") or disable ("0") the power-save mode.
Room temperature
Change "room_temp" variable to enable ("1") or disable ("0") the local temperature reading module. This requires a BMP-280 sensor to be installed using the I2C connector.
Check this other post for details on sensor installation:
Some theme configuration has been enabled by allowing to choose between different eyes as a background image.
Use the variables "eyesA" and "eyesB" specify one of the following values to change the background image expression of PAL:
"happy"
"angry"
"surprised"
"sad"
"happy""angry""surprised""sad"
"eyesA" is used as the default background and "eyesB" will be used as a transition when voice recognition is activated and PAL is talking.
The default value for "eyesA" is "surprised" and it will change to "happy" when a command is recognized.
Customizable commands
Adding your own commands to PAL is simple using the "comandos" function.
Every audio recognized by SpeechRecognition is sent as a string to the "comandos" function, which then filters the content and triggers one or another matching command.
Just define all the possible strings that could be recognized to trigger your command (note that sometimes SpeechRecognition provides wrong or inaccurate transcriptions).
Then define the command that is triggered if the string is matched.
def comandos(msg):
# LAMP ON
if any(keyword in msg for keyword in ["turn on the lamp", "turn the lights on","turn the light on", "turn on the light", "turn on the lights"]):
turnLAMP("on")
os.system("aplay '/root/upload/PAL/mp3/Turn_ON_lights.wav'")
Activation keyword
You can customize the keywords or strings that will activate command functions. If any of the keywords in the list is recognized, the whole sentence is sent to the "comandos" function to find any specific command to be triggered.
For the case of PAL v0.2, these are the keywords that activate it (90% it's Paypal):
You can change this to any other sentence or name, so PAL is activated when you call it by these strings.
PAL voice
Use the sample audio file "PAL_full" below (also in the github repo in /mp3) as a reference audio for CoquiAI-TTS v2 voice cloning and produce your personalized voices:
Below are a few examples of queries and replies from PAL:
"Hey PAL, turn on the lights!""Hey PAL, turn the lights off"
Future releases (To-Do list)
I will be developing these features in my personal assistant, and will be updating the open-source release every now and then. Get in touch via github if you have special interest in any of them:
Advanced menu: allow configuration and manually triggering commands.
IoT devices: include all Shelly and Sonoff HTTP API commands.
Time query: requires cloning all number combinations...
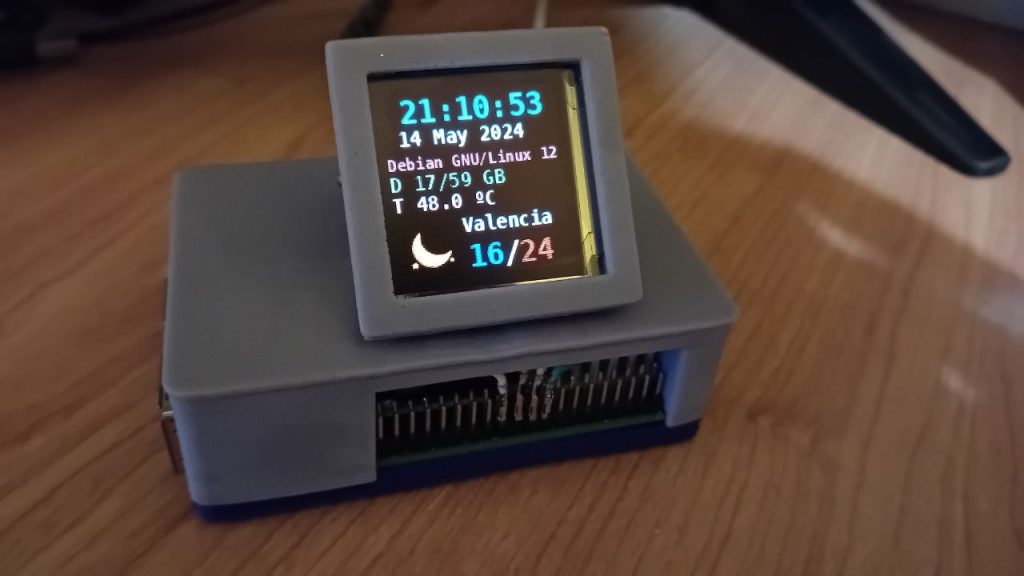
I keep experimenting with the UNIHIKER board by DFRobot and it’s incredibly fast to make things work in it. Today I’ll show you how to set up on-screen real-time temperature display in two minutes using a BMP-280 module and zero programming.
Content
Prerrequisites
Here's the trick. I was expecting you already had a few things working before starting the countdown:
Download and install Mind+, DFRobot's IDE for UNIHIKER. On Linux, it is a .deb file which does take a while to install: https://mindplus.cc/download-en.html
Solder a BMP-280 temperature and pressure module and connect it to the I2C cable. You might need to bend your pins slightly as the connector seems to be 1mm nano JST.
In Mind+, go to the Blocks editor and open the Extensions menu.
Go to the pinpong tab and select the pinpong module (which enables interaction with the UNIHIKER pinout) and the BMP-280 module extension, for interaction with the temperature module.
Go back to the Blocks editor and start building your code block. Just navigate through the different sections on the left hand side and drag all you need below the Python program start block:
pinpong - initialize board.
bmp280 - initialize module at standard address 0x76.
control - forever block (to introduce a while True loop).
unihiker - add objects to the display. I firstly add a filled rectangle object to clear previous text, then add a text object. Specify X,Y coordinates where every object will be displayed on the screen and its color.
bmp280 - read temperature property. Drag this inside the text field of the text object.
python - (optional) add a print to show the data on the terminal. I included all other sensor values.
control - add a wait object and wait for 1 second before next loop. All of it should look something like this (click to enlarge)
Launch
And that's all your program done, without any programming! Press RUN above and see how it loads and displays in your UNIHIKER screen. Touch the sensor with your finger to see how values change with the increase in temperature.
Wasn't that only 2 minutes? Let me know via Twitter ; )
The small and efficient form factor of the UNIHIKER makes it really easy to craft a case for it.
For my smart home asssistant I was looking for an android-like style, and the DFRobot logo is perfect for the UNIHIKER, making tribute to their developers.
Content
Github Repo
I've released a github repository where I will be open-sourcing all the model files and people can contribute with their own, so feel free to create a pull request and share your designs!
But AI world is moving so fast that today I’m bringing an evolution that completely exceeds the previous post, with complex voice generation and cloning in a matter of seconds and multilingual: Coqui-AI TTS.
Configure the other options (tick the boxes: Cleanup Reference Voice, Do not use language auto-detect, Agree)
Request cloning to the server (Send)
Installation
Another strength of Coqui-AI TTS is the almost instant installation:
You'll need python > 3.9, < 3.12.
RAM: not as much as for image generation. 4GB should be enough.
Create a project folder, for example "text-2-speech". Using a Linux terminal: mkdir text-2-speech
It's convenient to create a specific python environment to avoid package incompatibilities, so you need python3-venv. I'll create an environemtn called TTSenv: cd text-2-speech python3 -m venv TTSenv
Activate the environment in the terminal: source TTSenv/bin/activate
If you only need voice generation (without cloning or training), install TTS directly with python: pip install TTS
Otherwise, install the full repo from Coqui-AI TTS github: git clone https://github.com/coqui-ai/TTS cd TTS pip install -e .[all]
Checking language models and voices
First thing you can do is to check the available models to transform text into voice in different languages.
Type the following in your terminal:
tts --list_models
No API token found for 🐸Coqui Studio voices - https://coqui.ai
Visit 🔗https://app.coqui.ai/account to get one.
Set it as an environment variable `export COQUI_STUDIO_TOKEN=`
Make sure that the output folder exists, then check your result. The first time you'll get several files downloaded, and you'll have to accept Coqui-AI license. Next, voice generation only takes a few seconds:
Voice cloning
Lastly, the most amazing feature of this model is the voice cloning from only a few seconds of audio recording.
Like in the previous post, I took some 30 seconds of Ultron's voice from the film Avengers: Age of Ultron.
Sample in spanish:
Sample in english:
Now, let's prepare a python script to set all needed parameters, which will do the following:
Import torch and TTS import torch from TTS.api import TTS
Define memory device (cuda or cpu). Using cpu should be enough (cuda might probably crash). device="cpu"
Define text to be generated. txt="Voice generated from text"
Define the reference audio sample (a .wav file of about 30 seconds) sample="/voice-folder/voice.wav"
Call to TTS model tts1=TTS("model_name").to(device)
import torch
from TTS.api import TTS
# Get device ('cuda' or 'cpu')
device="cpu"
#Define text
txt="Bienvenido a este nuevo artículo del blog. Disfruta de tu visita."
#txt="Welcome to this new block post... Enjoy your visit!"
#Define audio sample
sample="../my-voices/ultron-es/mix.wav"
#sample="../my-voices/ultron-en/mix.wav"
#Run cloning
tts1 = TTS("tts_models/multilingual/multi-dataset/xtts_v2").to(device)
tts1.tts_to_file(txt, speaker_wav=sample, language="es", file_path="../output/ultron-es.wav")
Run it from the TTS folder where the repo was installed:
cd TTS python3 TRW-clone.py
Results
Here I drop the results I got on my first tests.
Spanish:
English:
And with a couple of iterations you can get really amazing results.
Any doubts or comments you can still drop me a line on Twitter/X
Today I’m bringing you the second chance that I’ll give Shelly. My first Shelly Dimmer blew up for excess temperature inside a connection box, but another Shelly 2.5 controlling two lights is holding fine, also fitted in the wall.
Maybe the difference is the extra 5ºC that they withstand, so I’m going to fit a wall plug with switch and scheduler using a tiny Shelly 1, and just hope it survives.
Apart from the tiny size, Shelly are easy to configure, so we’ll also see how to control them locally via the HTTP API.
Content
Requirements
My goal is to enable a wall plug that I can control and schedule via WIFI, in my case, to manage the electrical water heater. This is what I'll use:
Shelly 1.
Two wire electric cable (line and neutral).
Male plug.
Female plug socket.
Assembling material for a case (3D printer, plywood, etc).
Shelly 1Electric cableMale plugFemale plug socket (front)Female plug socket (back)Assembly support printed in 3D
Electric connection
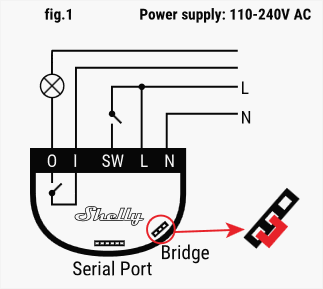
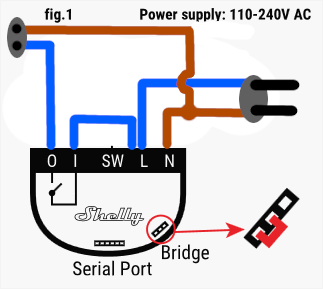
Let's look at Shelly's user manual and see how we need to make the connections:
The idea for this standard schematic is to connect Shelly 1 to a light bulb and its switch, where every symbol means the following:
L: line
N: neutral
SW: switch
I: input
O: output
As I want to enable a plug socket, the schematic will vary slightly, as I will not be using any switch and I can connect the input directly to the line. On the other hand, and for I reason I ignore, there is no cabling inside the connection box, so I bring the electric line from another plug using the cable... In the end, it all ends like this:
TIP! I'd say that I confused the cable color norm, but it is not important in this case as its a closed circuit and it will work anyways.
Assembly
You might see that I made a small 3D support to guide the cabling, as well as a lid to cover the void around the socket. Modelling every part in 3D, with real measures, helps to distribute the space properly and ensure that your solution fits:
I'll leave here the 3D .stl models ready to send to your slider software.
Finally, this is how it all looks crafted in place. It's not the perfect fit, but it does the job I needed.
Internet connection
Let's now see how to bring the Shelly 1 to life and control it locally.
Opposite to Sonoff, Shelly makes it much easier and you just need to follow the user manual.
Power Shelly 1 using the male plug.
This will activate an AP (Access Point) or Wi-Fi network with an SSID looking like "shelly1-01A3B4". Connect to this Wi-Fi network using a smartphone or PC.
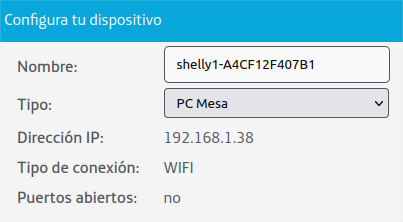
Once connected, use a web browser to access the IP at 192.168.33.1 and it will take you to Shelly's web interface for device configuration.
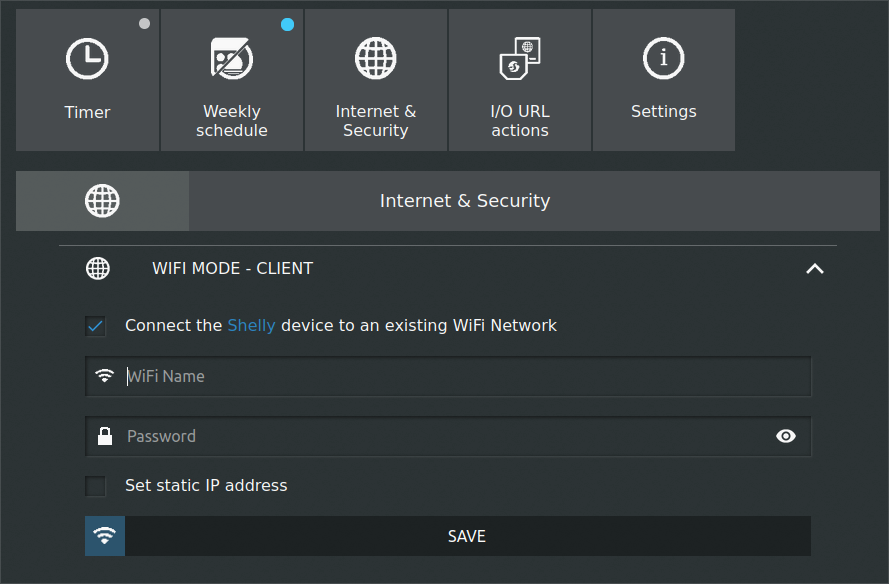
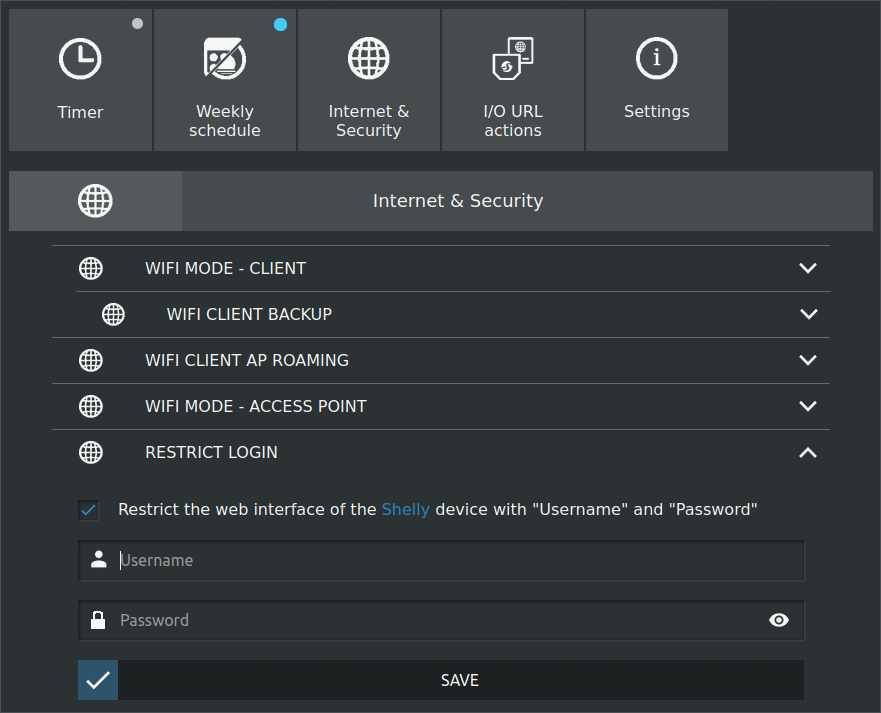
Once in, you must config the device (inside Internet & Security menu) so that it automatically connects to your local Wi-Fi network, as well as it is recommended to restrict access with username and password.
We're all set to communicate with Shelly 1 locally.
Shelly HTTP API usage
To use the command of the HTTP API you must know the device IP in your local network.
Find IP in the router
You can access the network map in your router, usually from the address http://192.168.1.1
The address and the password should be in some sticker in your router. Then you'll see your device with a name like shelly1-XXXXXXXXXXXX:
Find IP using nmap
In a terminal you can use the tool nmap to scan your local network.
Download it if not done yet: sudo apt-get update sudo apt-get install nmap
Scan your network (using sudo you'll get the MAC address, which is useful as the IP could change when restarting the router) sudo nmap -v -sn 192.168.1.0/241.0/24
Send HTTP requests to the device
Shelly's HTTP API is well documented in their website:
The value 0 in the URL matches te number of the relay or internal switch in the Shelly. In this case there is only one, but in the case of Shelly 2.5 you have two relays, so you can call them individually changing this value.
In this case, the URL defines the following schedule rule parameters:
HHMM: hour and minute that activate the rule
0123456: days of the week when the rule is active
on/off: status that the rule triggers
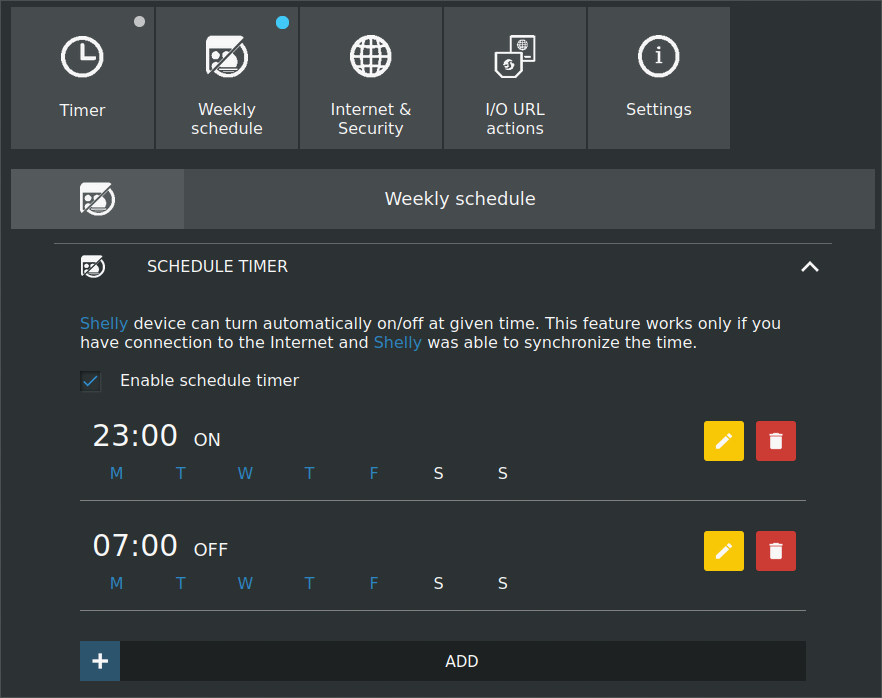
This way, to schedule the on and off of the device (except during weekends), you could send a request like this one:
curl -X GET http://192.168.1.XX/settings/relay/0?schedule_rules=2300-01234-on,0700-01234-off
Obviously you can also configure the schedule rules from the web interface, or just check the commands worked:
And that would cover all of it. Jump off and fill your house with tiny Shellys completely customizable. Any questions or comments on Twitter 🐦 please! (though given what's going on with the X thing, who knows how long I'll last...)
It all started as an exercise of curiosity, wondering if the attack of the Kerch bridge in Crimea was seen from space.
To my surprise, this might be one of the least visible attacks occurred during the war in Ukraine.
With every news, I checked the publicly available satellite imagery from the European Space Agency and found evidence of many of the reports. Satellite images are purely objective. There is no manipulation or speech behind.
This is absolutely opposite to taking one side or another. This is about showing the reality and the scale of war. The one and only truth is that violence and war has to be condemned in all its forms and prevented with every minimum effort one can do.
#WarTraces start in Ukraine, because it’s close to Europeans, 24/7 on TV, and affecting many powerful economies. But there are many ongoing conflicts in the world. Many that seem to be forgotten. Many we don’t seem to matter or care about. Many that have to be stopped as well as this one.
Follow me on 🐦 Twitter to know when this post is updated!
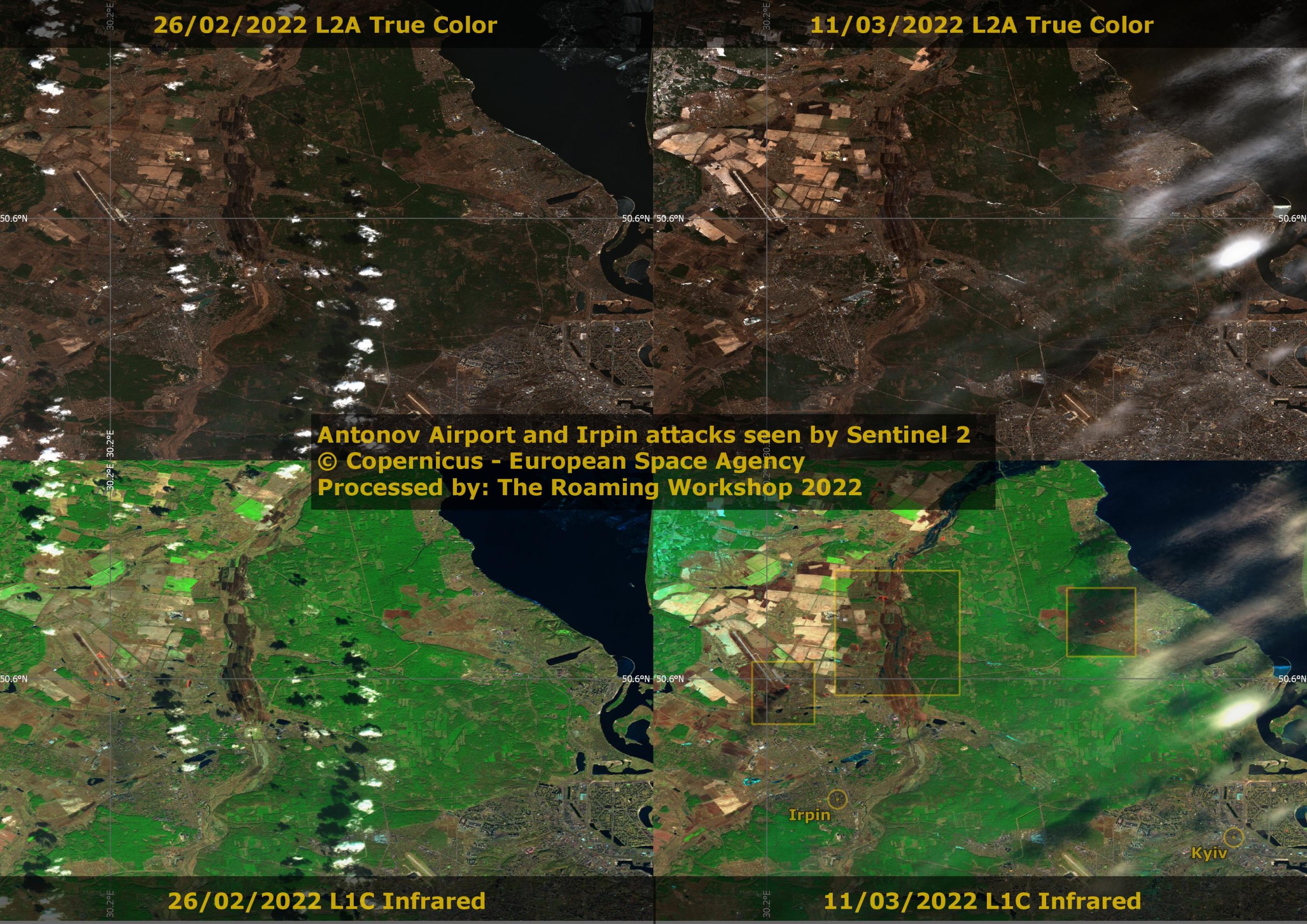
First Russian targets were aerodromes so air combat was neutralized. Antonov International Airport involved a tough battle from day 1
Verkhnotoretske village was an intense front for the first month, hardly 20km away from Donetsk
Mariupol was badly bombed at the start of the conflict. See the difference of usual infrared signal versus fires caused by bombs.
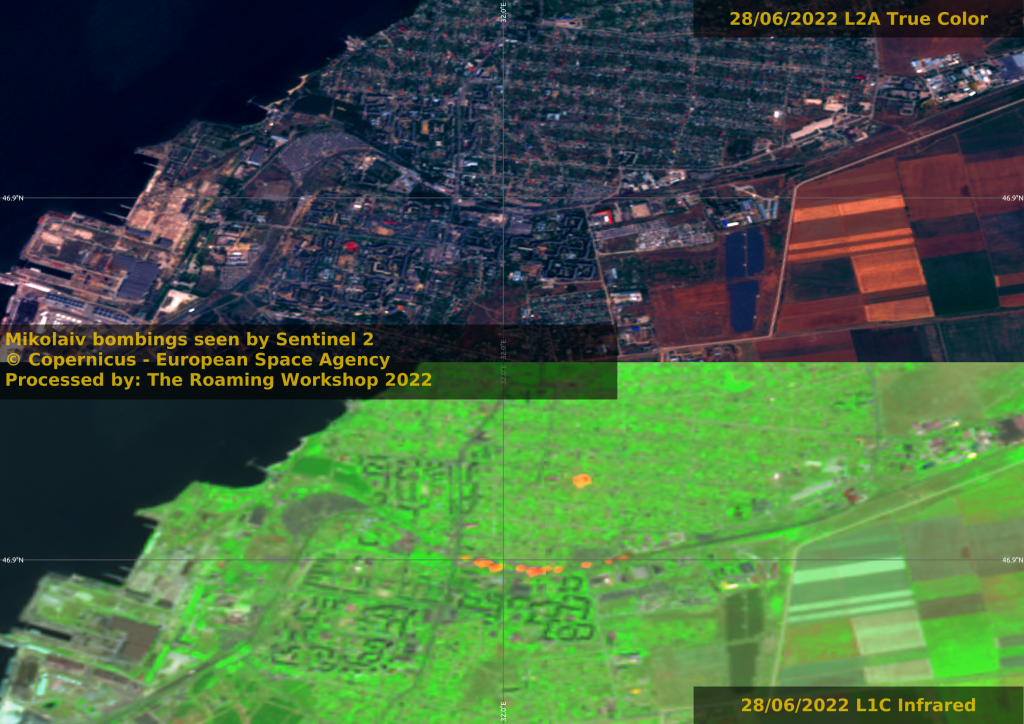
Mikolaiv's government building was half destroyed and 38 people died on 29th March.
South of Zaporizhzhia is the biggest nuclear power plant in Europe. It was early attacked and occupied in March. Further combats, like this one in August, could cause a nuclear catasthrope.
Claimed Crimea is connected to continental Russia via the Kerch bridge. A bomb-truck caused it's partial destruction in October 2022.
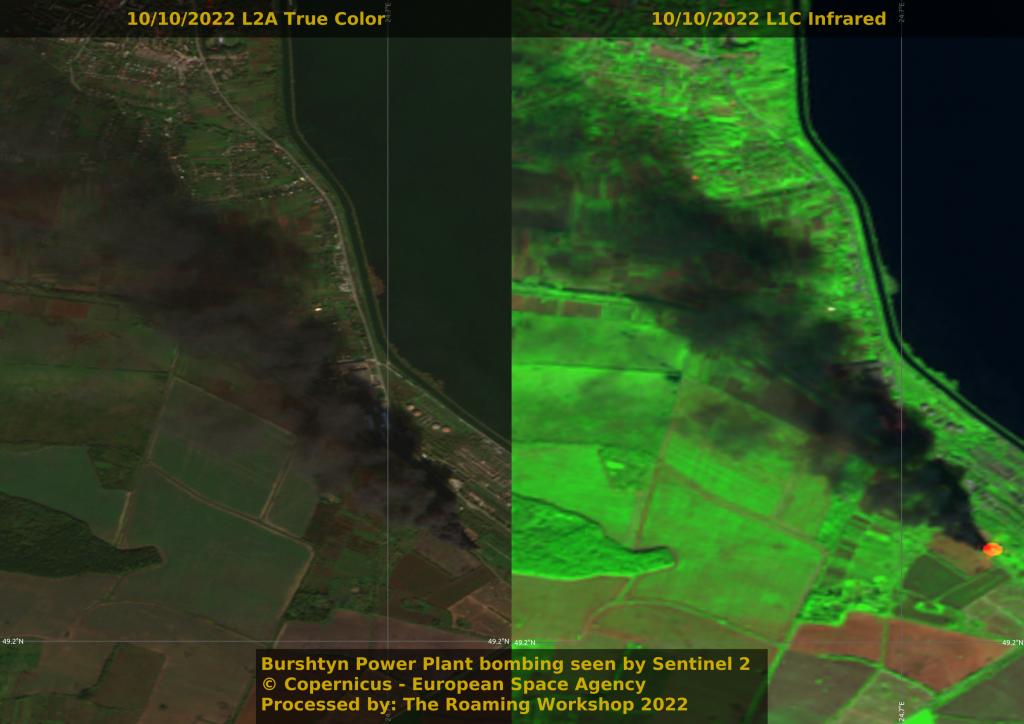
The attack in Kerch bridge led to a change in strategy and critical infrastructure for electricity and water have been targeted in sight of the coming winter.
It's usually cloudy in Ukraine, but these clouds aren't usual. The trails left behind aircrafts are also seen from space, providing information on their routes and height. Residential streets in Bakhmut, key location for Donbas' offensive, are resulting the scene of fierce combats. Europe's biggest salt mine, in Soledar, consists of 200km of 30m high tunnels, useful to house troops and war equipment during winter, hardly 15km away from Bakhmut.
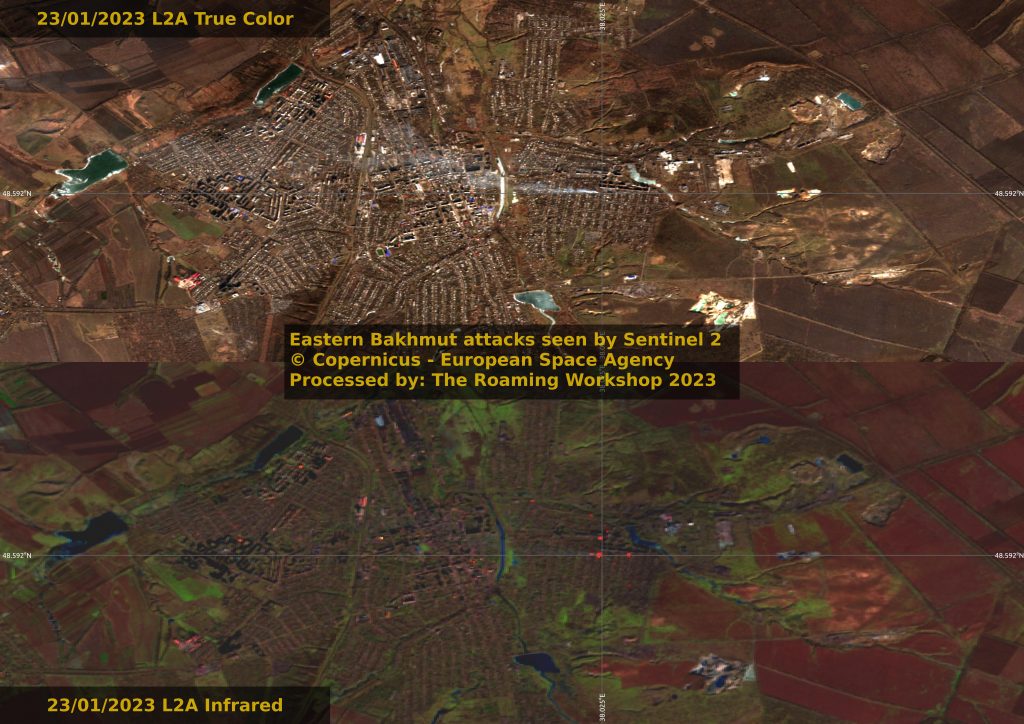
One month since I first spotted the battle for Bakhmut on a residential neighbourhood to the East.
Infrared activity in Bakhmut doesn't cease being the hardest front of the war so far From 10th October 2023, the brutal attempts to capture Adviidka continues to cause deaths.
On November 6th 2022, attacks over refugee camps ended in 9 people killed (3 of them children). People has been displaced from their homes after destroying most major settlements. You can see there were no camps in this area in 2015.
Late 2017 involved intense bombing of cities presumably occupied in northern and eastern Syria.