PAL is a simplified version of my python home assistant that I’m running in the DFRobot UNIHIKER which I’m releasing as free open-source.
This is just a demonstration for voice-recognition command-triggering simplicity using python and hopefully will serve as a guide for your own assistant.
Current version: v0.2.0 (updated september 2024)
Features
Current version includes the following:
- Voice recognition: using open-source SpeechRecognition python library, returns an array of all the recognised audio strings.
- Weather forecast: using World Meteorological Organization API data, provides today's weather and the forecast for the 3 coming days. Includes WMO weather icons.
- Local temperature: reads local BMP-280 temperature sensor to provide a room temperature indicator.
- IoT HTTP commands: basic workflow to control IoT smart home devices using HTTP commands. Currently turns ON and OFF a Shelly2.5 smart switch.
- Power-save mode: controls brightness to lower power consumption.
- Connection manager: regularly checks wifi and pings to the internet to restore connection when it's lost.
- PAL voice samples: cloned voice of PAL from "The Mitchells vs. The Machines" using the AI voice model CoquiAI-TTS v2.
- UNIHIKER buttons: button A enables a simple menu (this is thought to enable a more complex menu in the future).
- Touchscreen controls: restore brightness (center), switch program (left) and close program (right), when touching different areas of the screen.
Installation
- Install dependencies :
pip install SpeechRecognition pyyaml - Download the github repo:
https://github.com/TheRoam/UNIHIKER-PAL - Upload the files and folders to the UNIHIKER in /root/upload/PAL/
- Configure the
PAL_config.yamlWIFI credentials, IoT devices, theme, etc. - Run the python script
python /root/upload/PAL/PAL_v020.pyfrom the Mind+ terminal or from the UNIHIKER touch interface.
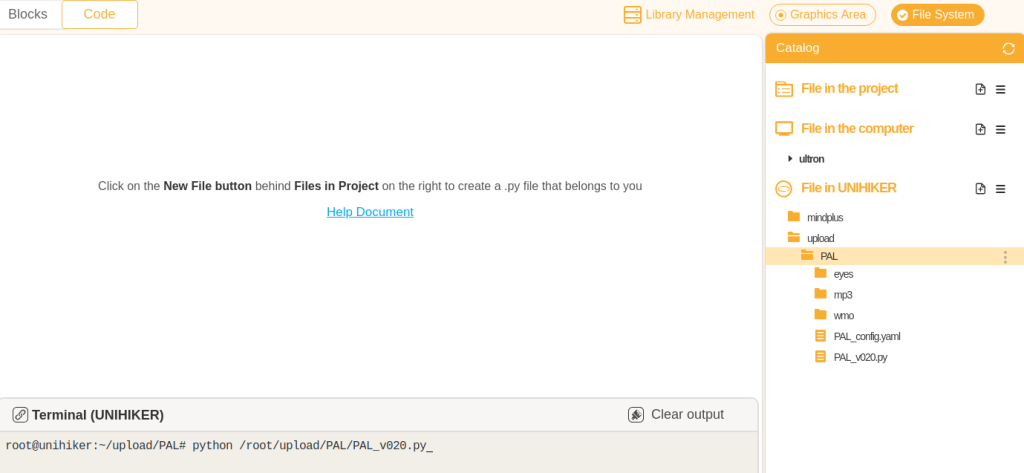
If you enable Auto boot from the Service Toggle menu , the script will run every time the UNIHIKER is restarted.
https://www.unihiker.com/wiki/faq#Error:%20python3:%20can't%20open%20file…
Configuration
Version 0.2.0 includes configuration using a yaml file that is read when the program starts.
CREDENTIALS:
ssid: "WIFI_SSID"
pwd: "WIFI_PASSWORD"
DEVICES:
light1:
brand: "Shelly25"
ip: "192.168.1.44"
channel: 0
light2:
brand: "Shelly25"
ip: "192.168.1.44"
channel: 1
light3:
brand: "Shelly1"
ip: "192.168.1.42"
channel: 0
PAL:
power_save_mode: 0
temperature_sensor: 0
wmo_city_id: "195"Location
The variable "CityID" is used by the WMO API to provide more accurate weather forecast for your location. Define it with the parameter wmo_city_id
You can choose one of the available locations from the official WMO list:
https://worldweather.wmo.int/en/json/full_city_list.txt
IoT devices
At the moment, PAL v0.2.0 only includes functionality for Shelly2.5 for demonstration purposes.
Use variables lampBrand, lampChannel and lampIP to suit your Shelly2.5 configuration.
This is just as an example to show how different devices could be configured. These variables should be used to change the particularities of the HTTP command that is sent to different IoT devices.
More devices will be added in future releases, like Shelly1, ShellyDimmer, Sonoff D1, etc.
Power save mode
Power saving reduces the brightness of the device in order to reduce the power consumption of the UNIHIKER. This is done using the system command "brightness".
Change "ps_mode" variable to enable ("1") or disable ("0") the power-save mode.
Room temperature
Change "room_temp" variable to enable ("1") or disable ("0") the local temperature reading module. This requires a BMP-280 sensor to be installed using the I2C connector.
Check this other post for details on sensor installation:
https://theroamingworkshop.cloud/b/en/2490/
Other configurations in the source code:
Theme
Some theme configuration has been enabled by allowing to choose between different eyes as a background image.
Use the variables "eyesA" and "eyesB" specify one of the following values to change the background image expression of PAL:
- "happy"
- "angry"
- "surprised"
- "sad"




"eyesA" is used as the default background and "eyesB" will be used as a transition when voice recognition is activated and PAL is talking.

The default value for "eyesA" is "surprised" and it will change to "happy" when a command is recognized.
Customizable commands
Adding your own commands to PAL is simple using the "comandos" function.
Every audio recognized by SpeechRecognition is sent as a string to the "comandos" function, which then filters the content and triggers one or another matching command.
Just define all the possible strings that could be recognized to trigger your command (note that sometimes SpeechRecognition provides wrong or inaccurate transcriptions).
Then define the command that is triggered if the string is matched.
def comandos(msg):
# LAMP ON
if any(keyword in msg for keyword in ["turn on the lamp", "turn the lights on","turn the light on", "turn on the light", "turn on the lights"]):
turnLAMP("on")
os.system("aplay '/root/upload/PAL/mp3/Turn_ON_lights.wav'")Activation keyword
You can customize the keywords or strings that will activate command functions. If any of the keywords in the list is recognized, the whole sentence is sent to the "comandos" function to find any specific command to be triggered.
For the case of PAL v0.2, these are the keywords that activate it (90% it's Paypal):
activate=[
"hey pal",
"hey PAL",
"pal",
"pall",
"Pall",
"hey Pall",
"Paul",
"hey Paul",
"pol",
"Pol",
"hey Pol",
"poll",
"pause",
"paypal",
"PayPal",
"hey paypal",
"hey PayPal"
]You can change this to any other sentence or name, so PAL is activated when you call it by these strings.
PAL voice
Use the sample audio file "PAL_full" below (also in the github repo in /mp3) as a reference audio for CoquiAI-TTS v2 voice cloning and produce your personalized voices:
https://huggingface.co/spaces/coqui/xtts

TIP!
You can check this other post for voice cloning with CoquiAI-XTTS:
https://theroamingworkshop.cloud/b/en/2425
Demo
Below are a few examples of queries and replies from PAL:
Future releases (To-Do list)
I will be developing these features in my personal assistant, and will be updating the open-source release every now and then. Get in touch via github if you have special interest in any of them:
- Advanced menu: allow configuration and manually triggering commands.
- IoT devices: include all Shelly and Sonoff HTTP API commands.
- Time query: requires cloning all number combinations...
- Wikipedia/browser query: requires real-time voice generation...
- Improved animations / themes.
Any thoughts, issues or improvements, I'll be happy to read them via github or Twitter!